Can We Prompt an LLM to Uncover its Dreams of Electric Sheep?by Lucia Mocz, Ph.D.Jun 7, 2023Jun 7, 2023
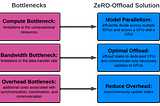
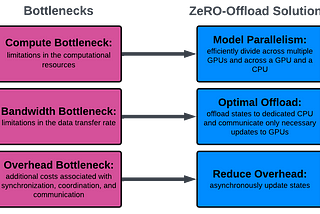
Performance bottlenecks in deploying LLMs—a primer for ML researchersby Lucia Mocz, Ph.D.May 10, 2023May 10, 2023
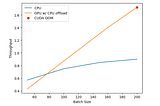
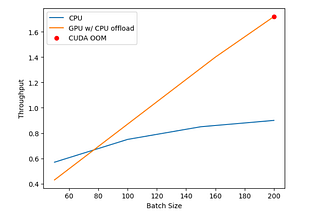
Squeeze more out of your GPU for LLM inference—a tutorial on Accelerate & DeepSpeedby Beite “Jupiter” ZhuApr 22, 20231Apr 22, 20231
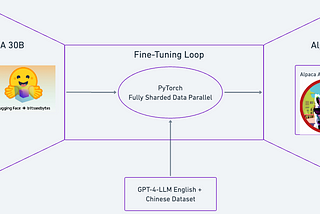
Fine-tuning a model to speak English and ChineseAt Preemo, we’ve created a model that understands and produces both English and Chinese — by using an efficient, faster form of…Apr 19, 2023Apr 19, 2023
Three traits of a task you can automateWhere will automation plug in? 1 of 3 in our Coding automation series.Apr 10, 20231Apr 10, 20231
Three ways to think about coding automationAI/ML tech is moving fast. Whether you’re an engineer, CTO, or somewhere in between, you’re likely wondering how to prepare for today and…Apr 10, 2023Apr 10, 2023